AI tools for lora training
Related Tools:
fal.ai
fal.ai is a generative media platform designed for developers to build the next generation of creativity. It offers lightning-fast inference with no compromise on quality, providing access to high-quality generative media models optimized by the fal Inference Engine™. The platform allows developers to fine-tune their own models, leverage real-time infrastructure for new user experiences, and scale to thousands of GPUs as needed. With a focus on developer experience, fal.ai aims to be the fastest AI tool for running diffusion models.
AvatarStudio
AvatarStudio is an AI tool that allows users to generate custom AI avatars by uploading selfies with different angles. The tool then builds a studio based on the uploaded photos and assists users in crafting the perfect prompt to generate unique avatars. AvatarStudio offers a cost-effective solution for creating custom AI avatars, providing 50 shots for $10 with a custom trained model and 4K generation capabilities. Users can unleash their creativity and design avatars that perfectly capture their unique style.

Google Gemma
Google Gemma is a lightweight, state-of-the-art open language model (LLM) developed by Google. It is part of the same research used in the creation of Google's Gemini models. Gemma models come in two sizes, the 2B and 7B parameter versions, where each has a base (pre-trained) and instruction-tuned modifications. Gemma models are designed to be cross-device compatible and optimized for Google Cloud and NVIDIA GPUs. They are also accessible through Kaggle, Hugging Face, Google Cloud with Vertex AI or GKE. Gemma models can be used for a variety of applications, including text generation, summarization, RAG, and both commercial and research use.

Flux LoRA Model Library
Flux LoRA Model Library is an AI tool that provides a platform for finding and using Flux LoRA models suitable for various projects. Users can browse a catalog of popular Flux LoRA models and learn about FLUX models and LoRA (Low-Rank Adaptation) technology. The platform offers resources for fine-tuning models and ensuring responsible use of generated images.
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.
AniGen AI
AniGen AI is an online AI application that generates anime characters for free. It uses advanced artificial intelligence algorithms to create unique and customizable anime characters. Users can easily design their own anime characters by selecting various features such as hair style, eye color, and clothing. AniGen AI provides a fun and creative way for anime enthusiasts to bring their characters to life.
ImageCreator
ImageCreator is a professional generative-AI plugin for Photoshop that allows users to create beautiful art in minutes. With its user-friendly interface and powerful features, ImageCreator is the perfect tool for artists of all levels. ImageCreator offers a variety of features, including: * **TXT2IMG:** Generate images from text prompts. * **IMG2IMG:** Edit and enhance existing images. * **FILL:** Fill in missing parts of images. * **Prompt Editing:** Provides positive and negative prompt input, and a personal notebook editor. * **ControlNet:** Support multiple control models and process settings to work together. ImageCreator is the perfect tool for creating unique and stunning art projects. With its powerful features and user-friendly interface, ImageCreator is the perfect tool for artists of all levels.
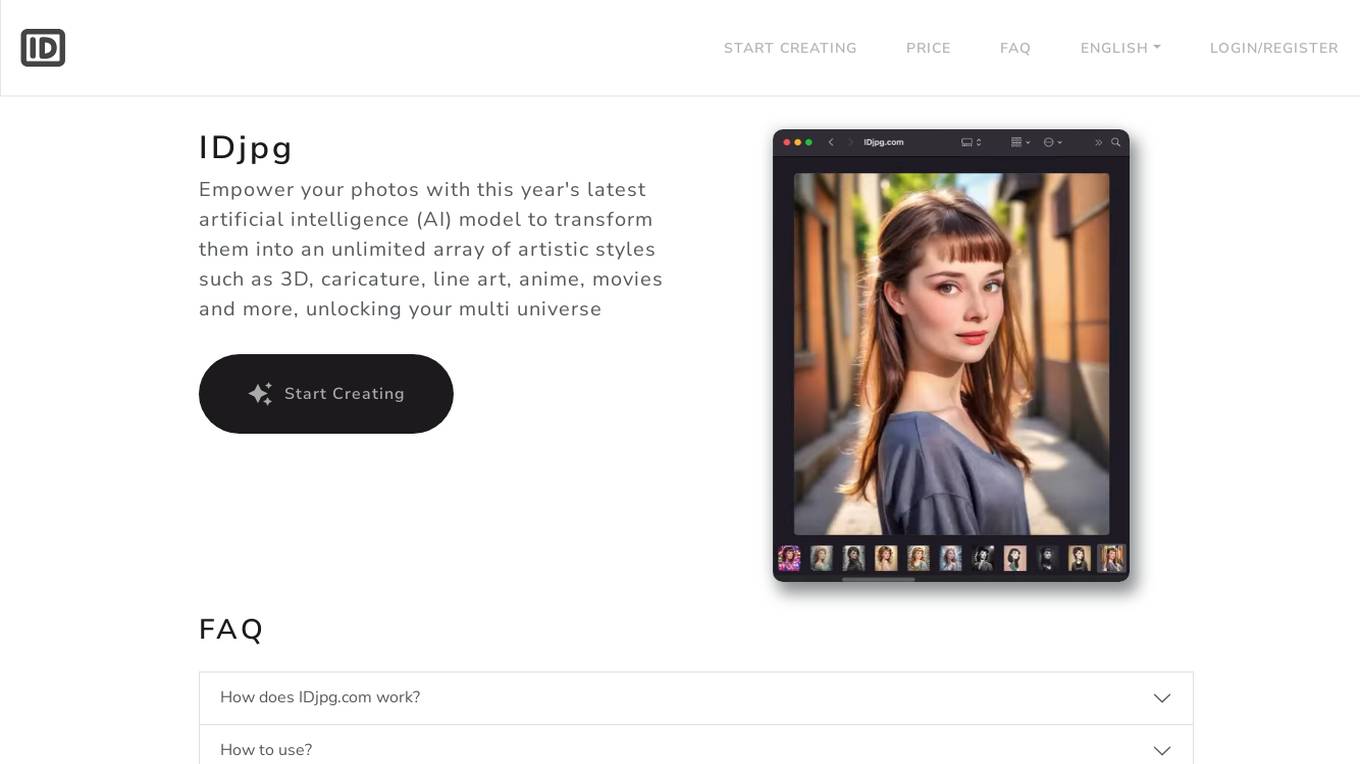
IDjpg
IDjpg is an AI-powered photo editing tool that allows users to transform their photos into a variety of artistic styles, including 3D, caricature, line art, anime, and movies. The tool is easy to use and can be used to create unique and eye-catching images.
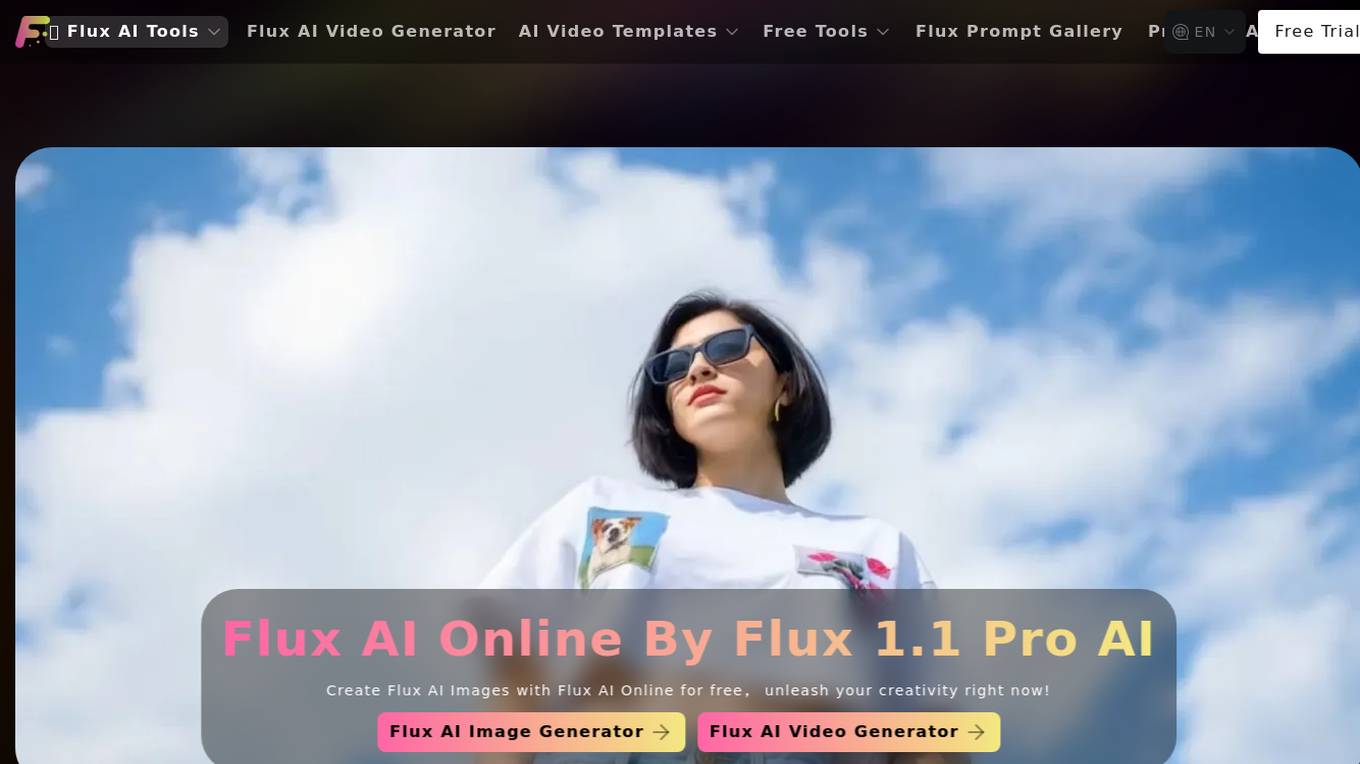
Flux AI Online
Flux AI Online is an advanced AI tool that offers a wide range of features for image and video generation. Users can create stunning images and videos using Flux Pro AI models such as Flux Lora Image Generator, Flux AI Anime Image Generator, and more. The tool also includes AI tools like Flux Canny/Depth AI for image processing and Flux Fill AI for image completion. With Flux AI, users can effortlessly enhance their creative workflow and bring ideas to life with high-quality visuals.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
Pixel Dojo
Pixel Dojo is an AI-powered platform that offers a wide range of tools for creators to generate AI art, videos, and character designs. With features like image enhancement, animation, inpainting, and more, Pixel Dojo aims to simplify and elevate the creative process for both beginners and advanced users. The platform integrates multiple professional-grade AI models to provide a seamless and intuitive experience.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
SiLLM
SiLLM is a toolkit that simplifies the process of training and running Large Language Models (LLMs) on Apple Silicon by leveraging the MLX framework. It provides features such as LLM loading, LoRA training, DPO training, a web app for a seamless chat experience, an API server with OpenAI compatible chat endpoints, and command-line interface (CLI) scripts for chat, server, LoRA fine-tuning, DPO fine-tuning, conversion, and quantization.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.
felafax
Felafax is a framework designed to tune LLaMa3.1 on Google Cloud TPUs for cost efficiency and seamless scaling. It provides a Jupyter notebook for continued-training and fine-tuning open source LLMs using XLA runtime. The goal of Felafax is to simplify running AI workloads on non-NVIDIA hardware such as TPUs, AWS Trainium, AMD GPU, and Intel GPU. It supports various models like LLaMa-3.1 JAX Implementation, LLaMa-3/3.1 PyTorch XLA, and Gemma2 Models optimized for Cloud TPUs with full-precision training support.
awesome-flux-ai
Awesome Flux AI is a curated list of resources, tools, libraries, and applications related to Flux AI technology. It serves as a comprehensive collection for developers, researchers, and enthusiasts interested in Flux AI. The platform offers open-source text-to-image AI models developed by Black Forest Labs, aiming to advance generative deep learning models for media, creativity, efficiency, and diversity.
Stable-Diffusion
Stable Diffusion is a text-to-image AI model that can generate realistic images from a given text prompt. It is a powerful tool that can be used for a variety of creative and practical applications, such as generating concept art, creating illustrations, and designing products. Stable Diffusion is also a great tool for learning about AI and machine learning. This repository contains a collection of tutorials and resources on how to use Stable Diffusion.
CareGPT
CareGPT is a medical large language model (LLM) that explores medical data, training, and deployment related research work. It integrates resources, open-source models, rich data, and efficient deployment methods. It supports various medical tasks, including patient diagnosis, medical dialogue, and medical knowledge integration. The model has been fine-tuned on diverse medical datasets to enhance its performance in the healthcare domain.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
LESS
This repository contains the code for the paper 'LESS: Selecting Influential Data for Targeted Instruction Tuning'. The work proposes a data selection method to choose influential data for inducing a target capability. It includes steps for warmup training, building the gradient datastore, selecting data for a task, and training with the selected data. The repository provides tools for data preparation, data selection pipeline, and evaluation of the model trained on the selected data.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.
template-repo
The template-repo is a comprehensive development ecosystem with 6 AI agents, 14 MCP servers, and complete CI/CD automation running on self-hosted, zero-cost infrastructure. It follows a container-first approach, with all tools and operations running in Docker containers, zero external dependencies, self-hosted infrastructure, single maintainer design, and modular MCP architecture. The repo provides AI agents for development and automation, features 14 MCP servers for various tasks, and includes security measures, safety training, and sleeper detection system. It offers features like video editing, terrain generation, 3D content creation, AI consultation, image generation, and more, with a focus on maximum portability and consistency.
rulm
This repository contains language models for the Russian language, as well as their implementation and comparison. The models are trained on a dataset of ChatGPT-generated instructions and chats in Russian. They can be used for a variety of tasks, including question answering, text generation, and translation.

flake
Nixified.ai aims to simplify and provide access to a vast repository of AI executable code that would otherwise be challenging to run independently due to package management and complexity issues. The tool primarily runs on NixOS and Linux, with compatibility on Windows through NixOS-WSL. It can automatically utilize the GPU of the Windows host by setting LD_LIBRARY_PATH in the wrapper script. Users can explore the tool's offerings through the nix repl, with the main outputs including ComfyUI, a modular node-based Stable Diffusion WebUI, and deprecated packages like InvokeAI and textgen. To enable binary cache and save time building packages, users need to trust nixified-ai's binary cache by adding specific lines to their system configuration files.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.